iOSDC Japan 2025に参加しました!
2025/09/19(金)-21(日)で開催されたiOSDC Japan 2025に参加しました!
iOSDCは2017年から参加してるのですが、今年はiOSDC Japan 10周年 & いつもと違う会場ということで、懐かしさもありつつ新鮮さもあって例年以上に参加して良かったと思えるカンファレンスでした。
LTでライブコーディングをしました
今年は「iOS 17で追加されたSubscriptionStoreViewを利用して5分でサブスク実装チャレンジ」というLTを行いました!

昨年、自社プロダクトにアプリ内課金を入れたのですが、その際に現代におけるアプリ内課金の実装方法について時間をかけて調査をしていて、iOS 17からStoreKitフレームワークにSwiftUI向けコンポーネントが同梱されているのを知ったのが登壇のきっかけでした。
5分の中でSubscriptionStoreViewを使うことで(ただ見た目がいい感じに作られるだけではなくて)何が嬉しいのかをちゃんと伝えられるか、ライブコーディングの見せ場を作れるかという点に結構苦戦したのですが、社内のエンジニアから沢山フィードバックをいただいて最終的にすごく良い形にできたのではないかなと思っています。
特にコメントアウトやコードスニペットを多用して5分に納めてもあまりライブコーディングとして魅力的ではないので、極力Paywallや契約状況判定などの実装は手で書きつつ、口も動かして...という感じで自分にとっては結構挑戦的な内容だったのですが、なんとか無事に実装を完了させられて見せ場も作れてかなと感じています。
パンフレットも書きました
パンフレット記事のプロポーザルも採択いただき「ユーザーフォント対応のためのカスタムフォントピッカー実装術」というパンフ記事も書きました。

こちらも自社アプリにフォントピッカーを実装するにあたって色々調査した内容をまとめたもので、iOSDCのパンフ記事書くのも初めてだったのですが、なんとか入稿期日までに執筆できて良かったです。
最初Re:VIEWで記事の執筆をしていたのですが、書き切ってから分量的に4ページに収まらなくなってしまったのと、利用していたテンプレートだと伝わりづらい部分があってレイアウトの調整が必要になったのですが、Re:VIEWのスキルが足りず意図したレイアウトに書き換えられなかったので記事を全てPagesで作り直したりしました。
もし次また機会があればRe:VIEW再挑戦したいですね。
他にも...
今回10周年なのもあって絶対スピーカーで参加したい...!と思いプロポーザルも普段より多めに出していて、パンフ記事1本、LT3本、レギュラートーク2本の6本のプロポーザルを書きました!
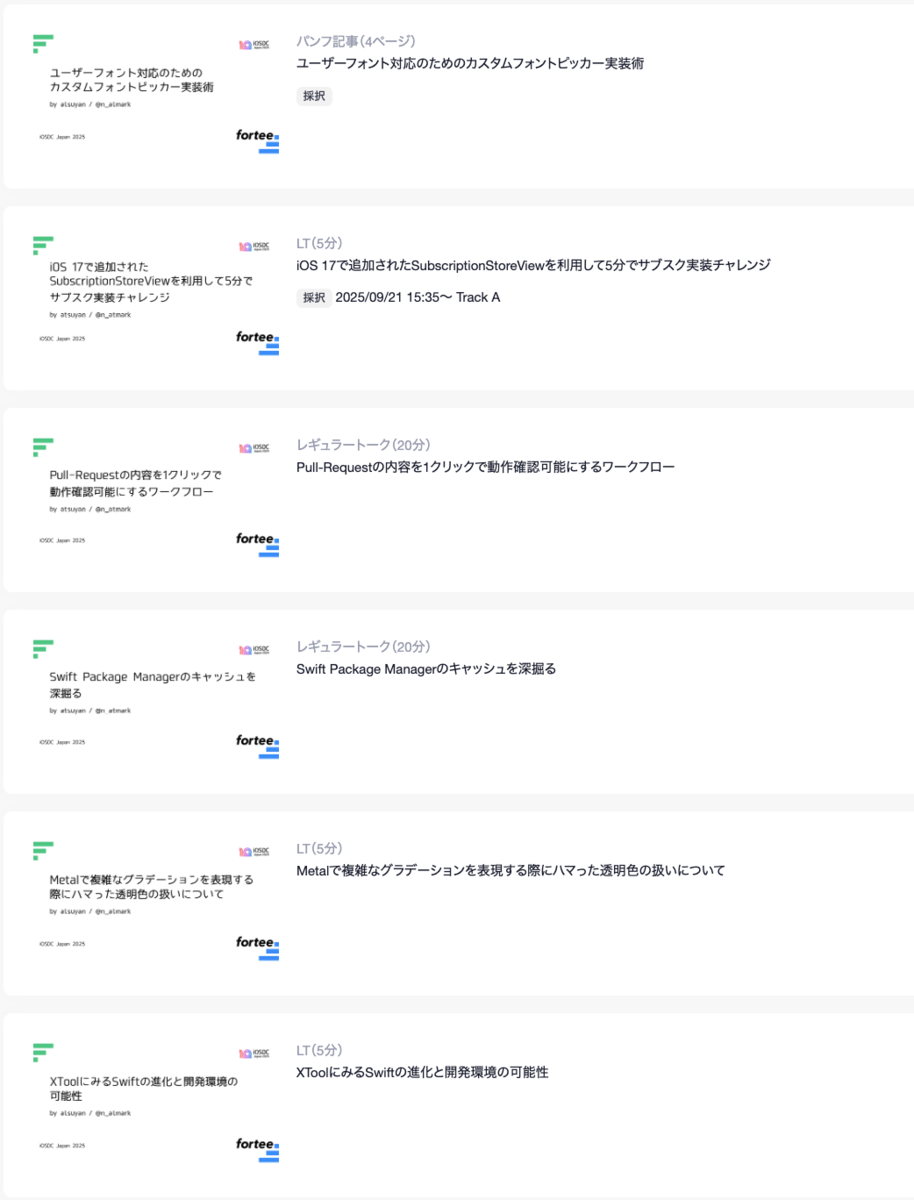
採択されなかった物も何かしらの形で発表したりできたらいいなあと思っています。
[宣伝]「 Pull-Requestの内容を1クリックで動作確認可能にするワークフロー」というプロポーザルの内容はextensionDCのday1で発表します!
ブース
自社ブースでは「SwiftUIと秘密の修飾子」というクイズアプリを制作して展示しました。

多くの方に楽しんでいただけて本当に良かったです!
このアプリ、実はiOSDC Japan 2025の開催が発表される前から構想があって、「絶対iOSDC Japan 2025のブース企画として展示するぞ!」と考えていたので、スポンサー募集が始まった際に会社としてブースを出してもらうために社内で稟議を通して予算をおろしてもらって...と働きかけをしていました。
また、沢山の同僚に自分の構想を参加者の皆さんに楽しんでもらえるようなコンセプトを作る部分やデザイン、作問などを協力してもらっています。 自分の思いつきで始まった企画なのですが、多くの方の協力で成り立っている企画なので本当に感謝しかないです。
他にもこのアプリに関しては色々話したい内容があるのですが、せっかくなので別の場所で発表したり、write-upも自社ブログから公開予定なのでそちらで公開できればと思います!
出身大学のOBOG・現役生が大集合した話
公立はこだて未来大学OB・OG・現役、のiOSエンジニアが大集合しました!
— yamaken (@yamakentoc) 2025年9月21日
年代は違えど皆あのガラス張りの校舎にいたんですね😭
#iosdc pic.twitter.com/X5YMudg5gz
自分は北海道函館市にある公立はこだて未来大学という大学出身なのですが、iOSDCに参加している同大出身のOBOGや現役生が集まって集合写真を撮りました。
半分くらい元々面識のない方達だったのですが、iOSコミュニティにおいてこんなにも未来大の輪が広がってるのが嬉しかったですし、新しい繋がりもできてiOSDC参加していて良かったなと改めて思いました。
自分が最初にiOSDCに参加したのは2017年で当時学部3年生でした。
当時、学内において自分の周りの学生でカンファレンスに参加している学生はほぼいなくて、自分はiOSDCに来ることで最新のiOS技術をキャッチアップしたり他大学で活躍している学生の方と交流したりというのが楽しかったのを覚えています。
自分の一つ下の後輩のyamakenは学生時代から自分と仲良くしてくれていて、自分の姿を見て同じようにiOSDCに参加してくれたり、その楽しかった経験をまた後輩に伝えてくれたり、徐々にiOSエンジニアを目指す方増えて、縁が縁を呼んでこれだけの人数が東京で開催されるiOSDCという場で介することができて本当に嬉しくなりました。
復刻デザインが嬉しかった話
自分が初参加した2017と、初めてiOSDCで登壇した2018年は特に思い入れがあるのですが、2017年デザインのパーカーがスピーカーのノベルティとして復刻したのが本当に嬉しかったです...!
ボトルウォーターの復刻デザインもすごく嬉しくて2017と2018デザインのものを沢山飲みました。
特に印象に残ってるトーク
半自動E2Eで手っ取り早くリグレッションテストを効率化しよう
E2Eテストがリグレッションを防止するのに大事なのは理解しつつもUIテストは壊れやすいしなんとなく苦手意識があったのですが、完全な自動化や綺麗な設計という理想を追い求めてる節が自分にもあることに気づいてハッとさせられました。
カスタムUIを作る覚悟
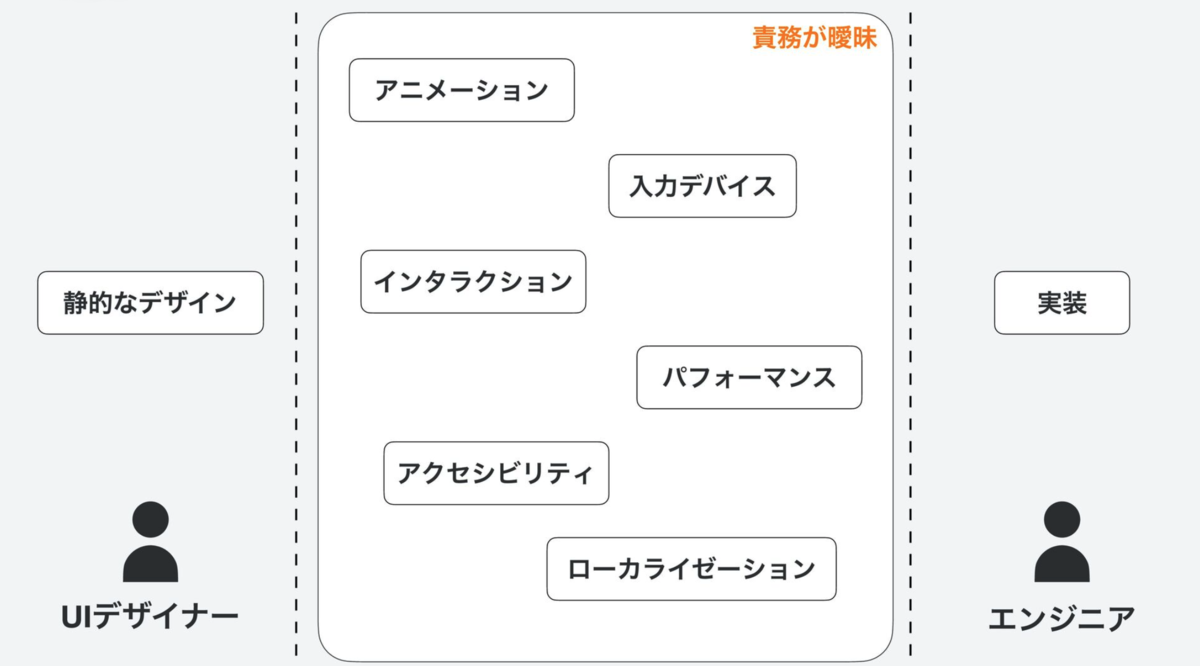

ここのスライドの内容が本当に心に沁みた...カスタムUIを作るかどうかの判断を「協業度」という観点から分析して言語化できるまつじすごい。
「iPhoneのマイナンバーカード」のすべて
mdocや JPKIPassContents などの発表内容も勉強になったのと、松館さんの「ぜひ一緒に日本のデジタル化を前に進めていただければ」というのにすごく胸が熱くなりました。これを言えるのすごくカッコいい
さいごに
iOSDC Japan 2026も楽しみです!
iOSDC Japan 2024に参加しました!
2024/08/22(木)〜24(土)で開催されたiOSDC Japan 2024に参加してきました!

スピーカーとして
今年はスピーカーとして参加することができ、day1の午後に「詳解UIWindow」というタイトルで発表を行いました。
前職時代にViewのInspectorを作ったり*1、現職でもマルチウィンドウ対応なアプリを開発*2する機会があり、UIWindowやUIWindowSceneについて触れることが多かったのですが、画面の最前面表示に関する正確な実装や特性についてインターネット上に十分な知見が無く実装しながら躓くことも少なくなかったです。
今年のiOSDCのプロポーザルを考える際に「UIWindowというクラスは知名度の割に利用機会が少なく、知見がたまりにくいのでは無いか。UIWindowの深掘りされた説明について価値があるのではないか」と考えプロポーザルを出してみました。
トークの採択連絡をいただいた際には嬉しさと共に、「(UIWindow自体は古くから存在するクラスなので) 2024年にUIWindowの発表通るんだ...」という驚きも実はありました。
当日のトークの構成に関しても悩んだのですが、UIWindowSceneとの関係性などについて図を用いてわかりやすく説明しつつUIWindowの特性に入っていく形にすることで、現代のアプリ開発における役割が分かりやすくなるかな?と思い、UIWindowや関連クラスの説明を厚めに用意してみました。
自分のトーク開始直前までどのくらいの人がUIWindowの話を求めているのだろう...というそわそわ感があったのですが、多くの方に聞きに来ていただいて自信を持って発表できました。

トーク聞いてくださった方、フィードバック・コメントくださった皆様ありがとうございました!
スポンサーとして
今年の2月に今まで所属していたクックパッド株式会社を退職し、ピクシブ株式会社に入社しました。 所属が変わったのもあって、今年はピクシブの宣伝をしていくぞ〜〜と意気込んでいました。

2日目の午後はスポンサーブースで法被を着て、クイズを出させていただきました。 登壇内容に合わせて「UIWindowの表示順」というクイズを用意しました。
クイズ挑戦していただいた皆様ありがとうございました!
参加者として
年々パワーアップしていくiOSDCに毎年わくわくしながら参加するのですが、今年はスポンサーブースのスタンプラリーがあって、スタンプラリーを理由にブースをたくさん回れたのが良かったなと思ってます。 たこ焼きも食べることができました🐙
去年は当日スタッフをしてたので、コロナ明けの軽食コーナーも初でした。ヨックモックのお菓子やGODIVAのチョコが置いてあって、糖分補給に高級菓子が食べられるのは嬉しかったです。
座談会形式のセッションがあったのも面白かったです。Strict Concurrencyについて豪華メンバーの多様な視点から議論されるのはすごく勉強になりました。
来年は
ここ数年は当日スタッフする年とスピーカーする年をいったり来たりしているのですが、当日スタッフとして参加した年は「来年はスピーカーしたい。スピーカーで知見を発表してコミュニティに貢献するんや!」という気持ちになり、スピーカーとして参加した年は「カンファレンススタッフでしか得られない栄養があるんだよな。来年はスタッフや!」という気持ちになっています。
果たして来年は...
10周年iOSDCも楽しみです!
このブログを書こうとはてなブログを開いたら去年の参加ブログを書こうとして諦めた形跡を発見...今年はちゃんと書きました...

2023年の振り返りと2024年の抱負
あけましておめでとうございます🎍
年末にブログ書こうと思っていたのに気づいたら年明けて1週間経ってました。
2023年の振り返りと2024年の抱負を書こうと思います!
2023年の振り返り
ボルダリング
2023年、一番大きな変化はボルダリングにハマったことだと思う。 会社の同僚に誘ってもらって始めたら見事にどハマりしてしまった。
ボルダリング、パズル的な頭を使う要素と身体能力の両方使うので面白いなと感じてる。 ジムごとに壁や課題の特徴が違ってて、いろんなジムを開拓するのも楽しい。

自分のインスタも気づけばボルダリングの動画ばっかり上げるクライミングアカウントになってた。


クライミングシューズも物足りなさを感じて2足目を買ってしまった。まさかこんな早く買い替えるとは思ってなかった。
11月にはノボロックの外岩講習に参加して外岩にも挑戦することができた。ジムと違って手足の置き場に悩んだり、ホールドと違って滑るので難しかった。
しまなみ海道
9月には夏休みを使ってしまなみ海道にサイクリングへ。
レンタサイクルで80kmくらいの道のりを走った。天気も良かったし、景色がすごく綺麗だった。 自分の足で移動するのは楽しい。
四国に行ったのも初めてだったけど、すごく良いところだった。また行きたい。
ISUCON初出場
ISUCON初参加楽しかった〜!
— あつや🍳 (@n_atmark) 2023年11月25日
ISUCON13 にクックパッド新卒メンバーで出場した。普段モバイルアプリ開発をメインでしているのでISUCONで扱う技術はあまり馴染みのないものも多いがその分、新しい技術分野に触れるきっかけになって楽しかった。
せっかく出るならちゃんとスコアを残したいと、チームメンバーと時間を合わせて4日くらい過去問を練習したり、当日使う環境構築用のスクリプト用意したりちゃんと準備して挑めたのが良かった。
初期スコアのまま終了になったら悲しいなと思っていたけど、最終スコア12,971で(トップのチームと比べると全然まだまだだけど)ちゃんとスコアを残せてよかった。
とはいえアプリケーション側の改善しか入れられなくて、DNS水責めは何もできなかったし3台あったサーバも1台しか使ってなかったのでもっと総合格闘技っぽい楽しみ方ができるようになりたいなと思った。また機会があれば出てみたい。
退職
退職します!お世話になりました!!!! pic.twitter.com/8lQK1ZsLyN
— あつや🍳 (@n_atmark) 2023年12月22日
2024年の1月で5年間勤めたクックパッドを退職することにした。12月末に最終出社で現在は有休消化中。
メインではモバイルアプリ開発のエンジニアとして働いていたが、ハードウェアの開発に携わったり、新規事業で「レシピ」と「かいもの」をつなぐような新しい価値を提供するためのサービス開発をしたり、採用に携わったり幅広く挑戦できた。
techlife.cookpad.com speakerdeck.com
5年間色々なことがあったし、沢山成長させてもらえたと思う。優秀で優しい良い人たちに囲まれて働けて良かった。
2024年の抱負
転職
2月からは新しい会社で働き始める予定である。初めての転職ということもあり、転職先で成果が出せるかドキドキしているけど、環境を変えて心機一転頑張りたい。
クックパッド時代の上司に「あつやさんは楽しんでいる時が成果が出る時ですね」と言われたことがある。 僕自身は作ることが好きで、作ったものによって人に貢献することが好きである。 プロダクトに貢献することでユーザーを喜ばせたり事業を伸ばしたり、学びを還元することで組織に貢献したり、そういった動き方ができているとき自分は楽しさを実感するので、次の会社でもこれは大事にしたい。
ボルダリング
去年1年ボルダリングして、横パンで6級→4級が登れるくらいになった。今年は横パンで3級を安定して登れるようになりたい。 去年外岩もデビューできたので、今年は名前付きの課題が登れるといいな。 そろそろコンペも出てみたい。あとリードクライミングも挑戦してみたい。
入院
実は来週から手術入院の予定がある。
一ヶ月くらい放置してた肩の腫れを診てもらうために整形外科行ったら、CTとエコーでは判明しなくて、明日別の病院でMRI検査になってしまった。大事にならないといいな。。。😇
— あつや🍳 (@n_atmark) 2023年10月27日
肩に脂肪腫ができてしまった。良性腫瘍の判定なのですぐに大事になるわけではないのだが、サイズが大きめのため悪化時にリスクがあるため摘出手術を受けることにした。
人生初の全身麻酔 & 手術 (入院も物心ついてからは初) なのですごくドキドキ。 今年の初詣は "無事に手術終わりますように" のお願いをしました。
さいごに
2024年もよろしくお願いします!
2022年振り返りと2023年の抱負
あけましておめでとうございます!
2022年の振り返りと2023年の抱負を書こうと思います。
2022年の振り返り
1月
Nellのマットレスを買いました。シングルベッドをダブルベッドに買い替えて睡眠環境がめっちゃ良くなった!


2月
新型コロナウイルスに罹った。。。
- コロナっぽい症状がでた時にどうしていいのか分からずパニックになったり、土日で空いてる病院なくて2万円払ってPCR受けたのはいい思い出
- 熱が引いた後も2~3週間くらいコロナ後遺症で咳喘息になってた
- ユニバ行く予定を諦めた😢
コロナ症状ある期間で体重が3kg落ちた

3月
静岡に行って人生初さわやかをしました。さわやかのハンバーグ、柔らかくて飲み物だった。また食べに行きたいな


INN THUNDERBOLT PROJECT BY FRGMT & POKÉMON に泊まった!黒カビゴンと黒ピカチュウのぬいぐるみをおうちにお迎えしました

PS5も買った!

4月
カンデオホテルズ大宮に連泊しました。カンデオホテルズはサウナが最高で大好きなホテルです

函館にも行きました。桜の季節の五稜郭はいいぞ


5月
ジムに通い始めました!今年のベストサブスク。金で買える健康は最高!

同じ部署のメンバーと福岡に旅行に行きました!福岡はご飯美味しくて最高。何回でも行きたい


6月
家庭用脱毛器を買いました。元々腕や脚の体毛濃くて割とコンプレックスだったのですが週1回半年続けてたら大分目立たなくなってきました。今年のベストバイ
7月
好きな女の子ができて楽しかった期。毎週遊びの予定を入れてたけど付き合ってからは1週間で振られてしまった😢👋

8月
iOSDCの準備で大忙し。大変だったけど会社のメンバーと一緒に資料作ったり発表練習会したり楽しかった。ブースの企画とかもやってたので、とにかくバタバタだった。
プライベートは傷心旅行を兼ねて金沢に行きました。金沢、駅前に観光地がまとまってて観光しやすかった。

ちょっと足を伸ばして新石川県立図書館まで行ったらすごくよかったです。1日時間潰せてしまう。また行きたいな

9月
iOSDCが3年ぶりのオフライン開催で楽しかったです。久しぶりに会う人も沢山いて懐かしい気持ちだった

iOSDC登壇お疲れ様を兼ねて潮見プリンスホテルに3泊引きこもってスプラトゥーンやったのも楽しかった。

10月
DroidKaigiの初オフライン参加しました。去年からAndroidも書いててDroidKaigi行ってみたかったので行けて良かった。

2月に行けなかったユニバにも行けて最高!!

11月
Cookpad TechConfにスタッフとして参加しました。多くの方が来場してくださって、活気を感じられたのが嬉しかったです。

札幌に旅行も行きました。ホテルエミシアのテレワークプランで4泊したんですが、電源アリ、軽食・フリードリンク付きのカフェで仕事して、疲れたら併設されてる温泉施設のサウナで整える環境が良かったです。またやろう

12月
イベント会場貸し切って忘年会しました。ジャンプOK・発声OKのライブ近年失われてしまっていたので楽しかった〜! gp.yokohama-coast.com
2日前に突然誘ってもらって、前日に航空券取って鹿児島旅行に行ったのもいい思い出。黒豚も魚も鳥刺しも白熊アイスも美味しかった。鹿児島また行きたい!


実家帰るついでに期限切れそうだった無料宿泊特典を使ってW大阪に泊まった!最高だったのでまた泊まりに行きたい


2023年の抱負
ジムは継続するぞ💪
- 健康大事。健康のために始めたんですが、「痩せた?」って言ってもらえるの普通に嬉しいので来年はもう少し体型絞ろうかな
旅行は好きなので引き続き行くぞ
- 2022年も色々なところに行ったけど2023年も色々なところに行って沢山美味しいものを食べるぞ!
- カメラ(Sony α7iii)を持ってるのだけど旅行の時とか全然持ち出せてないので、もう少し軽いカメラ買おうかなと考え中🤔 (GR IIIxが気になっている)
昔やってた弓道をまたやろうか考え中
活動の幅を広げたい。外にも出て行きたい
- モバイル以外にも手を出したいし、なんならエンジニアリング以外のサービス開発に必要な事もどんどんやっていきたい。
- あと、社内に引きこもりがちなのでなんとかしたい。社外向けに技術記事書いたりブログ書いたり学生時代の方がしてたよな…と思いつつ、元々内向的な性格がコロナで余計に内向的になっているので、もう少し社外に出て行きたい。。。
アイコンをなんとかしたい
- 色々なアカウントで使ってるtry! Swift 2018のRikoのフォトパネル持った写真、アイデンティティにもなってるんですが、今年で撮影から5年経ってしまいそろそろ年齢詐称気味なので、インターネットアカウントのアイコンをなんとかしたい!!

さいごに
今年も健康で楽しく過ごしたい!2023年もよろしくお願いします!
iOSDC Japan 2022で「施策基盤としてのディープリンク」という発表をしました! 〜ウラ話を添えて〜
ididblog
今年もiOSDCに参加してきました。3年ぶりのオフライン開催、すごく楽しかったです。2017年から参加してるので5年目のiOSDCでした。
自分の過去のiOSDCへの参加形態を振り返ってみると
- 2017年: スカラシップ枠 (ブログ)
- 2018年: レギュラートークスピーカー (ブログ)
- 2019年: 当日スタッフ (ブログ)
- 2020年: スポンサートークスピーカー (発表資料)
- 2021年: LTスピーカー (発表資料)
(2020年と2021年ブログ書くのサボってますね...私)
このような形で参加していて、さて今年はというとCfPを採択していただけて4年ぶりにレギュラートークのスピーカーとして参加することになりました🎉
2018年にレギュラートークスピーカーをした頃はまだ学生で、その時はデバイス管理の話をしてました (懐かしい...)
施策基盤としてのディープリンク 〜なめらかにアプリが開く体験のために〜

今年登壇した内容が「施策基盤としてのディープリンク 〜なめらかにアプリが開く体験のために〜」になります。
登壇ウラ話
実は最近、メイン業務はAndroidアプリ開発を行なっています。登壇の時に紹介を行ったレシピサービス クックパッド上で買物体験を提供するチームに所属しており、そこでAndroidアプリを書きつつ、iOSはチームメンバーのコードレビューに入ったり、趣味リファクタリングをする程度の関わり方になりつつあります。
iOS/Android両方経験のあるエンジニアということもあり施策基盤を用意するような関わり方も増えてきたのですが、実はエンジニアがディープリンクを一度仕組みとして用意してしまった後その後活用するのは施策オーナーが多く「アプリへの流入に対してどういう仕組みを活用できるのか」、「施策の効果を最大限発揮するためにどういう改善ができるのか」、「計測したい数値をどう把握できるようにすればよいのか」といった点に関してエンジニアと施策のオーナーの共通認識を取れていないケースが多いのでは?と感じるようになりました。
例えば、施策オーナーが言う 「ディープリンクを用意して欲しい」 は Firebase Dynamic Linksを使ったDeferred Deep Linkingに対応したダイナミックリンクが必要なのか、Custom URL Schemeのルーティングを実装して欲しいのか、はたまたUniversal Linksが必要なのか...
用語の認識を揃えるところから進めないと、お互い曖昧な認識のまま事が進み、施策開始のタイミングで必要なアプリへの流入経路が用意されていなかったということが発生しそうだと考えました。
ただ、ディープリンク関連の用語は似たような言葉も多く、列挙されてるだけではあまり理解が進まないと感じたので、最初は図を作って社内共有するところから手をつけ始めたました。

社内でも結構評判が良くて、「ディープリンク関連の用語の整理や施策に応じてどういう仕組みを活用できるのかはエンジニアにとって有益な知見になるのでは?」と考えるようになり今回のiOSDCでの登壇に繋がったのでした。
Twitterでいただいた感想
ありがたいことに沢山の方に登壇を見ていただき、Twitter上でも沢山感想をいただきました。(本当にありがとうございました!!!嬉しかったです!)
ディープリンクって特にアプリエンジニア以外に勘違いされがちだったり、理解されてないがちだからこういう言葉の説明されてると助かりますね #iosdc #b
— ダンボー田中📦 (@ktanaka117) 2022年9月10日
定義がとてもしっかりしていて自分が新卒の時に聞きたかったやつ〜〜〜ってなってる。#iosdc #b
— Shuhei (@shu26) 2022年9月10日
ディープリンク、特にビジネスとのやり取りで各リンクの仕様の違い、iOS/Androidの違い、さまざまな面で混乱しがちなので、挙動と実現する手段のまとめの発表が非常にありがたい✨#iosdc #b
— 神武 (@koooootake) 2022年9月10日
施策に関わる全メンバーに頭に入れてほしい話#iosdc #b
— あおい (@aomathwift) 2022年9月10日
雰囲気で理解していたので、概念と用語から活用例まで全て勉強になった https://t.co/pPrZWX490H
— Toshiki TAKEZAWA👻 (@to4iki) 2022年9月10日
いくつかピックアップさせていただいたのですが、自分の登壇の原点になった「ディープリンク関連の用語の整理や施策に応じてどういう仕組みを活用できるのかはエンジニアにとって有益な知見になるのでは?」に対して、登壇を見ていただいた方に自分の発表した知見を届けられたように感じて、登壇して良かったなと改めて思えました!
さいごに
#iOSDC Day1、昨日に引き続きブース出展を行なっております!
— Cookpad Tech Life (@cookpad_tech) 2022年9月11日
本日クックパッドブースでは、クックパッドアプリの開発の様子をデモで実演します 👨💻
・12:30~12:45 サンドボックスビルドのデモ実演
・13:50~14:05 ログ定義自動生成のデモ実演
ぜひクックパッドブースにお越しください! pic.twitter.com/aZlj5DCpZ8
実は、今年クックパッドのスポンサーブースの企画のリードをしてました。バックパネル作ったりテーブルクロス作ったりTシャツ作ったりパネル作ったり、イベントの企画したり、事前告知ブログ書いたり、@cookpad_tech のツイート運用したり!(この辺の深い話は会社のテックブログにでも書こうかな)
実は今年、弊社のiOSDCのスポンサー企画周りのリードをしてたのですが、さっきiOSDC会場に向けてブース用物品を一式発送したので肩の荷が一旦降りました🍵
— あつや🍳 (@n_atmark) 2022年9月8日
3ヶ月くらい準備に時間を使ってたのですが、ノベルティちゃんと封入業者に届いてるか心配になったり、当日スタッフが混乱しないか不安になったりしながらの日々だったり😇
今年のiOSDC、自分の発表してブース立って、レポート用に弊社メンバーの登壇写真撮って、自社の企画実行して、社のTwitterアカウント動かして、ってしてたら過去一バタバタなiOSDCになってしまったw
— あつや🍳 (@n_atmark) 2022年9月11日
当日も自分の登壇が終わると今度は社員メンバーの登壇を撮影したりブース企画したり、過去1バタバタなiOSDCでした (笑)
自分の登壇も同僚の登壇も、ブース運営も大きな問題なく3日間を乗り越えられてよかった!きっとiOSDC Japan 2022は自分にとっても思い出深いiOSDCになるんだろうなあ〜!来年に向けてまた頑張るぞ💪
2020年行ったところ、泊まったところ
あけましておめでとうございます。
2020年も終わるので何か記事を書こうと思っていたのですが、気づけば新年を迎えてしまっていました。
表題の通りで、2020年に行ったところや泊まったところをまとめてみようと思います。
1月
神戸
ここに泊まりました。温泉サウナ付きなので選んだのですが、結構よかったです。 お風呂上がりの休憩スペースでアイスやビールが売っていて、♨️ 🔜 🍺の体験が最高でした
夜景🔜神戸ご飯🔜温泉🔜ビールで完全優勝してしまった pic.twitter.com/6FaXO93RGs
— あつや🍳 (@n_atmark) January 13, 2020
神戸ハーバーランドにも近くて、ハーバーランドでも食事や観光を楽しめました。
夜景めちゃ綺麗じゃん pic.twitter.com/NWOc43GZrM
— あつや🍳 (@n_atmark) January 13, 2020
博多
わいわいswiftc 番外編ワークショップ #3 - 福岡 に参加するために博多に行きました
泊まったのはここ。なるべくお金をかけずに博多にいくぞ!という気持ちでの旅行だったので、飛行機はJALのマイルで、宿は博多駅から近くてリーズナブルなホテルを探していたら、ここを見つけました。 無料朝食がついてるのが嬉しかったです。朝食のゆでたまごが美味しくて、2回くらいおかわりしました🥚🥚
博多に行った時に2つ温泉にも入ってきました。
♨️♨️♨️ (@ 波葉の湯 - @namihanoyu2 in 福岡市, 福岡県) https://t.co/xhwQ62nvjo pic.twitter.com/NE6YRldt9K
— あつや🍳 (@n_atmark) January 26, 2020
みなと温泉は博多ふ頭にある温泉で、露天風呂から波の音を聴きながら入れたのが印象的でした。 お風呂上がりには九州のみどり牛乳をいただきました。
♨️♨️♨️ (@ 万葉の湯 - @manyo_hakata in 福岡市, 福岡県) https://t.co/ZgtGzJfKAd pic.twitter.com/jRjv3v2Pzu
— あつや🍳 (@n_atmark) January 27, 2020
万葉の湯は温泉リゾート施設のような感じになっていて、かなり大きな施設でした。 由布院温泉と武雄温泉の二つの源泉が一つの温泉施設で楽しめるようになっていて、お得ですね。 サウナもハーブサウナとスチームハーブサウナの二種類あったのが印象的でした。
2月
群馬
昨年は仕事の関係で群馬にいくことが多かったです。
ikaho-sakurai.com伊香保温泉来た (@ 旅館 さくらい in 渋川市, 群馬県) https://t.co/Jyv5cbPufl pic.twitter.com/r8qiJh8pY4
— あつや🍳 (@n_atmark) February 5, 2020
伊香保温泉の旅館さくらいに行きました。 2月の群馬すごく寒かったのですが、その分露天風呂が気持ちよかったです。 夜、朝両方温泉入ったのですが、朝風呂では冬の澄んだ空気と共に榛名・赤城の山々を一望できて気持ちがやすらぎました。
— あつや🍳 (@n_atmark) February 5, 2020
旅館で朝ごはんいただいたのですが、こちらも美味しかったです。
3月〜5月
ちょうどコロナが流行り出してきて、会社も完全リモートになったのがこの頃で、ひたすら家に引きこもってました
6月
札幌
1週間ほど札幌に行っていました。5末までずっと家に引きこもっていた結果、精神状態がおかしくなりそうで環境を変えたかったので、無理やり札幌旅行を計画しました。仕事もホテルにこもって札幌からリモートしていました。
泊まってたのはアパホテルです。この頃はGoToトラベルも無かったのですが、ホテルのテレワーク割プランで2500円/泊くらいで泊まれました。 大浴場付きでこの値段なら安いなと思ってここにしたのですが、大浴場が閉鎖中で悲しかったです。
余談ですが、学生時代からアパホテルをよく使っていて、ポイントが沢山貯まっていたので先日カタログギフトと交換しました。
www.new-chitose-airport-onsen.com
新千歳空港温泉、空港の温泉とは思えないほど本格的でいい湯でした。
7月
有給付与日が8月なのですが、7/1の時点で有給義務化で定められている年5日の年次有給休暇の取得義務に対して2日しか有給とっておらず7月に3日休む必要が出てしまったので、どこか旅行にいくことにしました。
どこか行きたい場所があったわけではなく、休暇をずっと家で過ごすのも忍びなかったので、JALのどこかにマイルを使って旅行することにしました。
どこかにマイルの結果、福岡空港を引き当てたので九州観光をしてきました。 とはいえ、博多には1月に行っているので博多から特急でいける長崎、大分(別府)をメインで観光することにしました。
という経路で移動しました。移動経路にかなり無駄があるように見えるのですが、区間変更できないので博多空港発着を考えると上記のようなルートになってしまいました。 特急はJR九州予約ネットから予約すると早割が効くので、よかったです。
長崎
カンデオホテルズ長崎新地中華街に泊まりました。これまでカンデオホテルズ名前も知らなくて、露天とサウナがあるからという理由で予約とったのですが、カンデオホテルズを知れたのが2020年一番の功績かもしれません。 このホテル、サウナがマジで良くて、サウナの環境といい水風呂の温度といい、脱衣所にウォータークーラー設置してあるのも良くて無限に最高でした。
後から知ったのですが、このホテルの代表の方がサウナ好きの方のようで(上の記事参照)、サウナ好きが作ったスカイスパ そりゃ最高にきまっとるやんけ〜!という具合です。
気づけばすっかりカンデオホテルズの虜になってしまいました。
大分
ここに泊まりました。ホテルの朝食ブッフェで出てきた地獄蒸しが美味しかったです。 せっかく別府に行ったので、別府の温泉にいくつか入ってきました。(ホテルの温泉大浴場も入ったのですがあまり記憶に残ってない。。。)
一つ目がひょうたん温泉というところで、19本の滝湯がずらーっと並んでいるのが圧巻でした。 お昼過ぎにここの温泉に行ったのですが、すごく天気が良くて夏っぽい青空を見ながら長時間ぼーっと露天風呂に入っていました。
お風呂上がりにいただいた温泉蒸しプリンとかぼすうどんが美味しかったです。
もう一つが別府温泉保養ランドで、ここはいろいろと凄かったです。 山の中にある(バスを30分以上乗って行った)温泉で、見た目も古い町役場のような見た目の温泉施設で、かなり年季が入ってました。
混浴の泥湯が有名な温泉でした。 水着の着用はもちろん無く、男女の仕切りもあってないような物なので、泥湯からでようとするとタオルで隠すのに一苦労みたいです。(自分が行った時は男性客だけでした)
泥を落とすためのシャワーしかないので髪の毛を湯船につけることができなかったり、入るのにやや敷居高く感じてしまうところもありますが、温泉はものすごく気持ちよかったです。「本物の温泉に入ってる!」って感覚でした。 番台のおじさんも優しくてまた行ってみたい温泉でした。
8月
東京
長崎で泊まったカンデオホテルズがすごく体験が良くて、近場にある新橋のカンデオホテルズにも泊まりに行きました。 ここも長崎とはまた少し違った感じのスカイスパでした。気持ち良くてよかったのですが、個人的ナンバーワンはまだ長崎です笑
9月
名古屋
実家に帰省しました。中部国際空港経由で帰省したので、中部国際空港の風(フー)の湯に行きました。 www.centrair.jp
温泉自体は新千歳空港温泉の方が好きなのですが、ここは滑走路に面していて飛行機を眺めながら温泉に入れるのでよかったです。
10月
1年で一番の転機があったのが10月なのですが、どこか旅行したりはしませんでした。
10月他に書くこともないので余談ですが、神奈川にある宮前平源泉 湯けむりの庄、近場で行けて好きな温泉なので月1~2くらいで行っています。
会社がフレックスなのですが、16~17時代で退勤する時は大体仕事終わりにここに行っています。
11月
札幌
実は今年2回目の札幌でした。北海道、ご飯が美味しいので何回でも行きたくなってしまう。 小樽運河みたり、ルタオでケーキ食べたり、お寿司食べたりしました。
🌃 (@ JRタワーホテル日航札幌 in さっぽろし, 北海道, 北海道) https://t.co/3jBacmAzyB pic.twitter.com/Yyb0mRW6PY
— あつや🍳 (@n_atmark) November 7, 2020
泊まったのはJRタワーホテル日航札幌でした。 客室が23階~34階に位置していて、お部屋のグレード関係なく札幌の街並みを楽しむことができました。
朝食ブッフェ海鮮丼 pic.twitter.com/EuR0aOBb8v
— あつや🍳 (@n_atmark) November 8, 2020
朝食ビュッフェで丼に海鮮盛り放題で、オリジナル海鮮丼を作って食べることができたのが面白かったです。そして美味しい。。。
埼玉
サウナで完全に整った……優勝です pic.twitter.com/luCzWetZg8
— あつや🍳 (@n_atmark) November 17, 2020
どんだけカンデオホテルズ泊まるんだよ。という感じですが大宮のカンデオホテルズに泊まりに行きました。 この時、さいたま市が宿泊促進キャンペーンをやっていて3,000円/泊の補助をGoToトラベルの値引きと別で受けることができたので、2500円/泊で泊まることができてお得でした(さらに地域共通クーポンももらえる)
サウナは言わずもがな最高でした。
12月
箱根
I'm at 箱根・芦ノ湖 はなをり in 箱根町, 神奈川県 https://t.co/c9pp3M0T5M pic.twitter.com/ojEKqtl1Zg
— あつや🍳 (@n_atmark) December 8, 2020
ロマンスなカーに乗って、箱根・芦ノ湖のはなをりに行きました。 宿泊予約サイトのReluxで2020年旅館人気ランキング1位になった宿で、設備の綺麗で全体的に木の温かみのあるお宿でした。 温泉はもちろん、足湯があったり、お部屋も部分的に畳が使われていて、ゆったりくつろげました。
小鉢取り放題ビュッフェおいしい🤤 pic.twitter.com/pdSOxdsE2g
— あつや🍳 (@n_atmark) December 8, 2020
夕飯はビュッフェスタイルで、小鉢取り放題だったのですが、この小鉢のお料理が美味しくて小鉢を沢山取りました。 これとは別でメインや汁物、デザートなどもあって満足度高かったです。
総評
GoToのおかげもあって普段なかなか泊まりづらい宿にも泊まることができました。 コスパよく旅行するのが好きで、学生時代はコストをできるだけ抑えつつ、値段に見合ったパフォーマンスを得られるかどうかという観点で旅行することが多かったのですが、Cost per performanceのパーセンテージ自体は維持しつつコストにベットすることでパフォーマンスも引き上げられるかどうかという観点で旅行するのも楽しそうだなと思うようになりました。 今年はホテルのクラブラウンジに行ってみたいので、ラウンジアクセスのある部屋に泊まるぞ!という気持ちで2021年もやっていこうと思います。
iOSDC2019に当日スタッフとして参加しました!

これは何
2019/9/5(木)~9/7(土)で開催されたiOSDC2019に当日スタッフとして参加したので、「当日スタッフはいいぞ。 」というのをブログで発信して、ぜひこのブログを読んだ方にも来年以降当日スタッフやってみてほしいな!という気持ちで、
モンスターハンターワールド:アイスボーンのダウンロード待ち時間が暇だったので 忘れないうちに、ブログにまとめようと思います!!
iOSDCも終わったので、しばらく旅に出ます!!!!!!探さないでください!!仕事には行きます! pic.twitter.com/ItFENyWMPH
— あつや🍳@iOSDC当日スタッフ (@n_atmark) September 7, 2019
なんで当日スタッフやろうと思ったの
昨年のiOSDC2018ではスピーカーとして参加したので、今年もスピーカーとして参加しようと思っていました。しかしCfPを通せず(実はそんなにネタが無くて、1つ絞り出してみたもののあえなく撃沈)一般参加しようと思っていました。 そんな時に、コアスタッフをされている会社の先輩の@su-さんから当日スタッフを誘われたので、申し込んでみることにしました。
当日スタッフの申し込み
当日スタッフは一般公募で、 @iosdcjpのツイートで募集されていました。
楽しい楽しいカンファレンスを支える当日スタッフも募集中です!
— iOSDC (@iosdcjp) August 2, 2019
当日会場に来て頂ければOK!
事前準備から関わるコアスタッフに興味がある方もまずは当日スタッフでお試しください。https://t.co/mpcjEJKayX#iosdc
なにやるの
- メインは担当(受付担当/部屋担当/HQ...)をしつつ、day0(前夜祭)の朝に会場準備をしたり、day2(最終日)の夜に片付けという内容です。
- 僕の担当はトラックAの部屋担当でした。(初スタッフで一番大きな部屋の担当になってしまい、初日は結構焦った💦)
- 当日の司会進行や、タイムキーパー、PA(映像音響)・参加者の方の誘導などをやりました。
- もちろん一人では無くて、各部屋担当が5~6名いて、部屋担当を指揮してくださるコアスタッフの方もいらっしゃるので、初めてでも全然問題なく担当をこなすことができました 🙆♂️(マニュアルも作ってもらえているので安心です!!何も心配いりません!!)
大変なの?
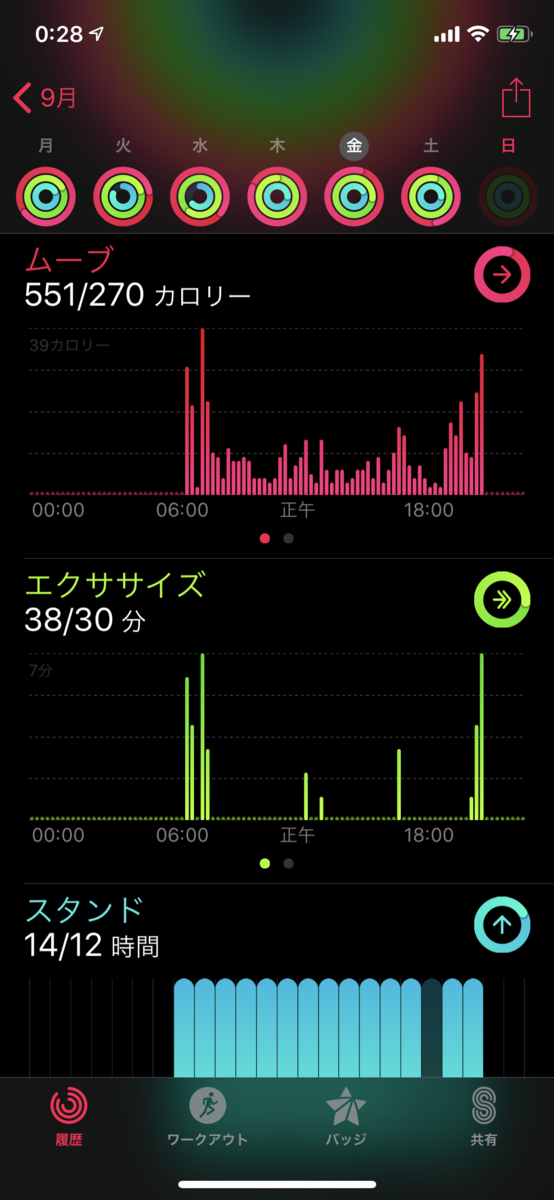
- これ見て!!!
| day0(前夜祭) | day1 | day2 |
|---|---|---|
 |
 |
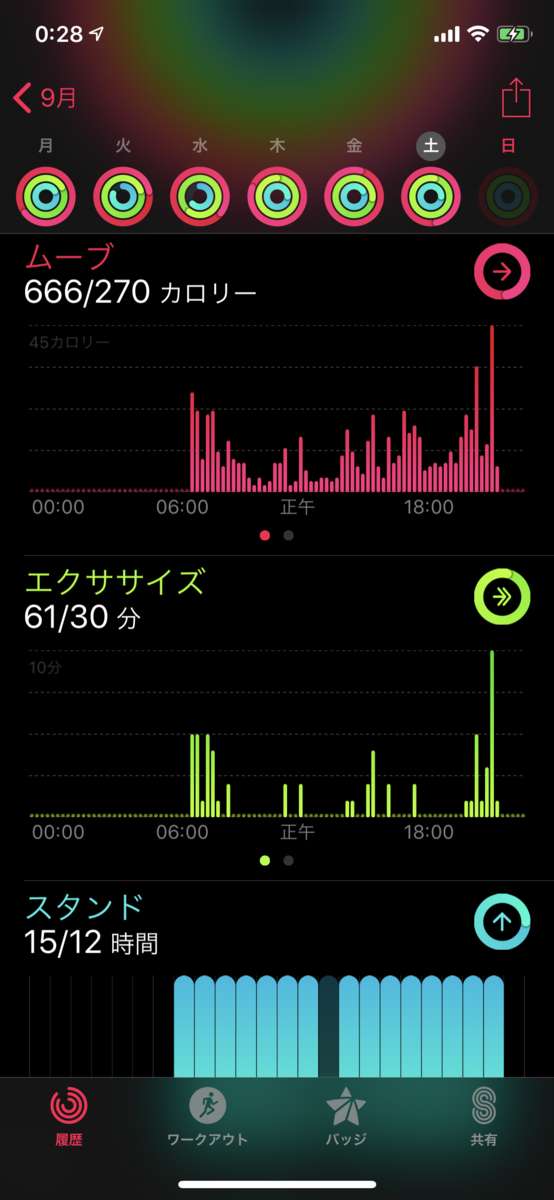 |
準備があった初日と、片付けをした最終日はやっぱり消費カロリー高めですね。初日の消費カロリー750kcalというのは、体重58kgの人が90分ランニングするのと同じくらいの消費カロリーだそうです。

これを大変と思うかどうかは人次第ですが..........................................................
僕はしっかり疲れました!!!
大変だけど良かったところ
カンファレンスの裏側を知ることができる
- 普段、参加者側で参加していると知れないようなことがたくさんあります...!!
- 「iOSDCの会場のトラックAとトラックBの結合はこうなってるのか〜」とか、
- 「こんなところにスタッフ控え室あったのか!!!」とか
- 「ノベルティの数こんなに多いの!?!?」とか
 (この箱全部、受付で配っていたトートバックが入ってます!!!)
(この箱全部、受付で配っていたトートバックが入ってます!!!) - 「録画・配信機材こんな風になってたのか!!」とか

- 普段、参加者側で参加していると知れないようなことがたくさんあります...!!
iOSDCの雰囲気を知ることができる!
- iOSDC初めての方こそiOSDCの当日スタッフおすすめです!!!!
スタッフの皆さんが優しい!!!
懇親会でどこのテーブルに行っても「スタッフお疲れ様でした!!」と言ってもらえる。最高!!🎉🎉🎉🎉
- これだけでスタッフやって良かったーーーーー!!と思える。オススメです!
なにより達成感が半端ないです!3日間、1日1日がすごく濃いので、やりきった感がすごい!
そしてビールが最高にウマい!!(しかも、iOSDCで提供されるビールは良いビールが揃ってる)
ここまで読んでくださった方、当日スタッフオススメです!!
また来年のiOSDCで!#ididblog